Introdução
Esse artigo é um resumo feito no intuito de servir como fixação dos conteúdos da matéria de Banco de Dados, no curso de Gestão da T.I - FAPAM 1º Período.
Aulas ministradas pelo professor Gabriel Ribeiro Diniz.
Os comandos SQL serão em sua grande maioria voltados ao SGBD PostgreSQL, já que é o SGBD estudado no curso.
Linguagem SQL
SQL (Structured Query Language) é uma linguagem de consulta estruturada, que é usada para manipular e recuperar dados de um banco de dados relacional. SQL é uma linguagem padrão para acessar e manipular bancos de dados.
Tem como base a álgebra relacional e o cálculo relacional.
O SQL é dividido em três partes principais:
DDL (Data Definition Language) - Linguagem de Definição de Dados
Define esquemas e tabelas, chaves primárias, chaves estrangeiras, exclusão de esquemas, tabelas e colunas, alteração de tabelas.
Diz respeito à estrutura das tabelas e esquemas no DB.
DML (Data Manipulation Language) - Linguagem de Manipulação de Dados
Consulta, inserção de dados no DB, exclusão de dados, alteração de dados. Diz respeito aos dados das tabelas do BD - CRUD 1
DCL (Data Control Language) - Linguagem de Controle de Dados
Define permissões.
SQL = DDL + DML + DCL
Principais comandos
DDL - Definição de dados: CREATE, DROP, ALTER.
DML - Manipulação de dados: SELECT, INSERT, UPDATE, DELETE.
DCL - Controle de dados: GRANT, REVOKE.
Conceitos
| Termo | Descrição |
|---|---|
| Table | Relação (tabela) |
| Row | Tupla (linha) |
| Column | Atributo (coluna) |
DDL - Data Definition Language
DDL - Data Definition Language (Linguagem de Definição de Dados) é usada para definir a estrutura que armazenará os dados. Define a estrutura das tabelas, índices, chaves primárias, chaves estrangeiras, etc.
Propriedades
A DDL permite não só a especificação de um conjunto de relações (tabelas), como também informações acerca de cada uma das relações, incluindo:
- O esquema de cada relação (estrutura)
- O domínio dos valores associados a cada atributo (
int,float,varchar, etc) - As regras de integridade de cada uma das relações
- O conjunto de índice para manutenção de cada uma das relações
- Informações sobre segurança e autoridade sobre cada relação
- A estrutura de armazenamento físico de cada relação no disco.
Criar banco de dados/esquema
Antes de qualquer tabela, é necessário criar um database (banco de dados) ou um schema (esquema). Em SQL uma base de dados (ou esquema) é identificada atravez de um nome. Os elementos do esquema incluem tabelas, restrições, etc.
Sintaxe:
CREATE DATABASE nome_do_banco;ou
CREATE SCHEMA nome_do_esquema;Exemplos:
CREATE SCHEMA Empresa;
CREATE SCHEMA Universidade;
CREATE DATABASE Hospital;Tipos de domínios
Numéricos
INTEGER: É um inteiro, originado da palavra integer (em inglês).
NUMERIC(p,d): É um número de ponto fixo cuja precisão é definida pelo usuário. O número consiste de dígitos (mais o sinal), sendo que dos dígitos estão à direita do ponto decimal.
Ex. NUMERIC(4,2): 42,00
SERIAL: Números inteiros auto incrementados.
Caracteres (Strings)
CHAR(n): É uma cadeia de caracteres de tamanho fixo, com o tamanho definido pelo DBA2. Abreviação de character (em inglês).
Ex. CHAR(12): Jack Sparrow
VARCHAR(n): É uma cadeia de caracteres de tamanho variável, com o tamanho definido pelo DBA. Abreviação de character varying (em inglês).
Booleano
BOOLEAN: É um tipo de dado que pode ter um dos dois valores possíveis: TRUE ou FALSE (verdadeiro ou falso).
Data/Tempo
DATE: É um tipo de dado que contém um ano (com 4 dígitos) mês e dia do mês sendo o formato "aaaa/mm/dd" o padrão do MySQL Workbench.
- ano (date) - retorna o ano de uma data
- Month (date) - retorna o mês de uma data
- Day (date) - retorna o dia de uma data
TIME: Representa um horário, com o formato "hh:mm:ss" (00:00:00).
Alguns SGBDs oferecem o domínio TIMESTAMP que contém a data (ano, mês e dia) e o horário (hora, minuto, segundo e milissegundos). Como é o caso do PostgreSQL.
Observações
- Uma chave estrangeira deve possuir o mesmo típo de domínio da chave primária correspondente.
- O valor nulo
NULLé um membro de todos os tipos de domínio, isto é, qualquer atributo pode receber o valorNULLexceto aqueles que são chaves primárias (restrição de integridade de entidade). - O SQL permite que a declaração de domínio de qualquer atributo inclua a especificação de
NOT NULL(não nulo), proibindo assim, a inserção de um valor nulo para esse tipo de atributo (obrigatório na PK).
Criar tabela
CREATE TABLE define a estrutura de uma tabela, suas restrições de integridade e cria uma tabela vazia.
Sintaxe:
CREATE TABLE nome_tabela (...);Exemplos:
CREATE TABLE empregado (atributo1 tipo, atributo2 tipo, ...);CREATE DATABASE EMPRESA;
CREATE TABLE DEPARTAMENTO (
CodDep SERIAL NOT NULL,
NomeDepVARCHAR(30),
PRIMARY KEY (CodDep)
);
CREATE TABLE FUNCIONARIO (
Matricula INTEGER NOT NULL,
Nome VARCHAR(30) NOT NULL,
Salario NUMERIC(8,2),
Cargo VARCHAR(15) DEFAULT 'Analista',
Estado CHAR(2),
Idade INTEGER, CodDepto INT,
PRIMARY KEY (Matricula),
FOREIGN KEY (CodDepto) references DEPARTAMENTO (CodDep) ON DELETE
NO ACTION ON UPDATE NO ACTION
);Criação de um código que gere códigos automáticos não e padrão SQL, mas caso seja necessario, pode-se utilizar o SERIAL na criação do campo. Muito utilizado em relações que possuiem IDs.
Exemplo:
CREATE TABLE cidade (
id_cidade SERIAL NOT NULL,
nome_cidade VARCHAR(100) NOT NULL,
PRIMARY KEY (id_cidade)
);Remover tabela
DROP TABLE remove todos os dados e a própria tabela, estando vazia ou não.
Sintaxe:
DROP TABLE nome_tabela;Exemplo:
DROP TABLE empregado;Alterar tabela
ALTER TABLE usado para alterar o esquema da tabela, permite modificar a estrutura de uma tabela existente.
Para operações de insersão, alteração e exclusão, atenção aos atributos e restrições de integridade.
Atributos chave não podem ser removidos!
Sintaxe:
ALTER TABLE nome_da_tabela;- Sintaxe básica para renomear tabela:
ALTER TABLE <nome da tabela> RENAME TO <novo nome da tabela>;Ex.:
ALTER TABLE empregado RENAME TO colaborador;- Sintaxe básica para inclusão de uma coluna:
ALTER TABLE <nome da tabela> ADD COLUMN <nome da coluna> <domínio e atributos>;Ex.:
ALTER TABLE funcionario ADD COLUMN identidade VARCHAR(10);Observe que...
- A instrução
ADD COLUMNadiciona uma nova coluna com o valor vazio para todas as linhas, isto é, sem nenhum valor armazenado. - O mesmo acontece quando há a criação de uma tabela (
CREATE TABLE). A princípio ela não está "povoada" com dados, está vazia, ausente de valores (em outras palavras: não há linhas/tuplas na tabela). - Os valores para as diversas linhas devem ser adicionadas através de instruções da DML (
INSERT INTO).
- Sintaxe básica para exclusão de uma coluna:
ALTER TABLE <nome da tabela> DROP <nome da coluna>;Ex.:
ALTER TABLE funcionario DROP identidade;- Sintaxe básica para alteração do nome de uma coluna:
ALTER TABLE <nom da tabela> RENAME COLUMN <nome da coluna> TO <novo nome da coluna>;Ex.:
ALTER TABLE empregado RENAME COLUMN sexo TO genero;- Sintaxe básica para alteração do tipo de uma coluna:
ALTER TABLE <nome da tabela> ALTER COLUMN <nome da coluna> TYPE <novo tipo>;Ex.:
ALTER TABLE funcionario ALTER COLUMN salario TYPE NUMERIC(10,2);Cuidado!
- Se já existir dados na tabela que não correspondem ao novo tipo, não será possível fazer a alteração de tipo.
- Se a coluna modificada for chave estrangeira em outra tabela, é preciso primeiro mudar na tabela que possui chave estrangeira.
Atributos
Chave Primária PRIMARY KEY: É um atributo ou conjunto de atributos que identifica unicamente uma tupla em uma relação. A PK é um atributo ou conjunto de atributos que não pode ter valores repetidos.
Chave Estrangeira FOREIGN KEY: É um atributo ou conjunto de atributos que faz referência a uma chave primária ou única em outra tabela. A FK é um atributo ou conjunto de atributos que pode ter valores repetidos.
A FK pode ser declarada com algumas opções de ação para deleção (ON DELETE) e atualização (ON UPDATE) de registros:
CASCADESET NULLSET DEFAULTRESTRICTNO ACTION
Restrição de Atributos (PostgreSQL):
NOT NULL- NN - O valor não pode ser nulo.DEFAULT <valor>- O valor padrão para o atributo caso não seja passado.UNIQUE- O valor não pode ser repetido, deve ser único.
Cláusulas da FK
ON DELETE
Cascata - CASCADE
Quando um registro é deletado da tabela referenciada, todos os registros que possuem a chave estrangeira referenciando o registro deletado também são deletados.
Sintaxe:
FOREIGN KEY cpf_cliente REFERENCES Cliente(cpf) ON DELETE CASCADEOnde cpf_cliente é o atributo da tabela atual e Cliente(cpf) é a tabela e atributo referenciado.
Restrito - RESTRICT
Quando um registro é deletado da tabela referenciada, a operação é restringida (da erro), ou seja, não é permitido deletar o registro pai se houver outros registros filhos á referenciando.
Sintaxe:
FOREIGN KEY cpf_cliente REFERENCES Cliente(cpf) ON DELETE RESTRICTNão faz nada - NO ACTION padrão - default
Quando um registro é deletado da tabela referenciada, um erro é exibido, e a operação de DELETE é revertida.
Sintaxe:
FOREIGN KEY cpf_cliente REFERENCES Cliente(cpf) ON DELETE NO ACTIONDefine como nulo - SET NULL
Quando um registro é deletado da tabela referenciada, a chave estrangeira é definida como NULL.
Sintaxe:
FOREIGN KEY cpf_cliente REFERENCES Cliente(cpf) ON DELETE SET NULLValor Padrão - SET DEFAULT
Quando um registro é deletado da tabela referenciada, a chave estrangeira é definida como o valor padrão DEFAULT.
Sintaxe:
FOREIGN KEY cpf_cliente REFERENCES Cliente(cpf) ON DELETE SET DEFAULTON UPDATE
Restrito - RESTRICT
Quando um registro é atualizado na tabela referenciada, a operação é restringida (da erro), ou seja, não é permitido atualizar o registro pai se houver outros registros filhos á referenciando.
Sinatxe:
FOREIGN KEY cpf_cliente REFERENCES Cliente(cpf) ON UPDATE RESTRICTDefine como nulo - SET NULL
Quando um registro é atualizado na tabela referenciada de modo que não exista mais a chave primária da tabela alterada, a chave estrangeira é definida como NULL.
Sintaxe:
FOREIGN KEY cpf_cliente REFERENCES Cliente(cpf) ON UPDATE SET NULLDefine como padrão - SET DEFAULT
Quando um registro é atualizado na tabela referenciada de modo que não exista mais a chave primária da tabela alterada, a chave estrangeira é definida como o valor padrão DEFAULT.
Sintaxe:
FOREIGN KEY cpf_cliente REFERENCES Cliente(cpf) ON UPDATE SET DEFAULTNão faz nada - NO ACTION padrão - default
Quando um registro é atualizado na tabela referenciada, de modo que a chave primária referenciada não exista mais, um erro é exibido, e a operação de UPDATE é revertida.
Sintaxe:
FOREIGN KEY cpf_cliente REFERENCES Cliente(cpf) ON UPDATE NO ACTIONConstraits
Constraits são todas as restrições que uma coluna pode ter (PRIMARY KEY, FOREIGN KEY, NOT NULL, UNIQUE, etc).
Adicionar constrait
Quando preciso adicionar uma constrait em uma coluna de uma tabela já criada.
Sintaxe
ALTER TABLE <nome da tabela> ADD CONSTRAINT <nome da restrição> UNIQUE;ALTER TABLE usuario ADD CONSTRAINT email_unico UNIQUE (email);email_unico é um nome arbitrário, ou seja, pode ser qualquer nome que você desejar. Esse nome será usado posteriormente para remover a restrição.
ALTER TABLE <nome da tabela> ALTER COLUMN <nome da coluna> SET NOT NULL;ALTER TABLE usuario ALTER COLUMN email SET NOT NULL;ALTER TABLE <nome da tabela> ALTER COLUMN <nome da coluna> SET DEFAULT <valor padrão>;ALTER TABLE usuario ALTER COLUMN email SET DEFAULT '--';Removendo uma constrait
Quando é necessário remover uma restrição de uma coluna.
Sintaxe
ALTER TABLE <nome da tabela> DROP CONSTRAINT <nome da restrição>;ALTER TABLE usuario DROP CONSTRAINT email_unico;ALTER TABLE <nome da tabela> ALTER COLUMN <nome da coluna> DROP NOT NULL;ALTER TABLE usuario ALTER COLUMN email DROP NOT NULL;ALTER TABLE <nome da tabela> ALTER COLUMN <nome da coluna> DROP DEFAULT;ALTER TABLE usuario ALTER COLUMN email DROP DEFAULT;Schemas
Schemas são conjuntos de tabelas dentro do banco de dados. Por padrão, o PostgreSQL cria um schema chamado public, onde todas as tabelas são armazenadas inicialmente. Porém é possível criar schemas personalizados para organizar melhor as tabelas.
Criar schemas
CREATE SCHEMA <nome_do_schema>;Exemplo:
CREATE SCHEMA empresa;Criar tabela em um schema
CREATE TABLE <nome_do_schema>.<nome_da_tabela> (...);Exemplo:
CREATE TABLE empresa.departamento (cod_dep SERIAL, nome_dep VARCHAR(30));Repare que para criarmos uma tabela em um schema específico, devemos informar o nome do schema seguido de um ponto . antes do nome da tabela.
Toda vez que for necessário referenciar uma tabela em um schema específico, deve-se informar o nome do schema seguido de um ponto . antes do nome da tabela.
Isso não ocorre quando a tabela está no schema padrão public. Se não passarmos o nome do schema, o PostgreSQL entende que a tabela está no schema public.
Remover schemas
DROP SCHEMA <nome_do_schema>;Exemplo:
DROP SCHEMA empresa;Remover base de dados (DB)
DROP remove toda a base de dados, incluindo todas as tabelas, dados, índices, etc.
Sintaxe:
DROP DATABASE nome_do_banco;Exemplo:
DROP DATABASE Empresa;
DROP DATABASE Hospital;
DROP DATABASE Universidade;Atenção! A instrução DROP DATABASE remove todos os dados, tabelas e relacionamentos na base de dados, e não é possível recuperar os dados após a execução dessa instrução!
DML - Data Manipulation Language
DML - Data Manipulation Language (Linguagem de Manipulação de Dados) é usada para gerenciar os dados armazenados em um banco de dados. Manipula os dados de uma tabela, como inserir, atualizar, excluir e selecionar.
Propriedades
A linguagem DML é composta por 4 operações de manipulação de dados:
- Inserção de dados -
INSERT - Exclusão de dados -
DELETE - Atualização de dados -
UPDATE - Seleção de dados (consulta) -
SELECT
Inserir Dados
INSERT INTO é usado para inserir novos registros em uma tabela.
Sintaxe:
INSERT INTO <nome da tabela> (coluna1, coluna2, ...) VALUES (valor1, valor2, ...);Exemplo:
INSERT INTO empregado (nome, salario, cargo) VALUES ('João', 2000.00, 'Analista');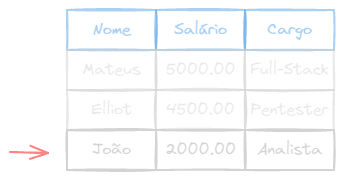
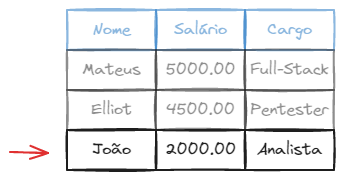
Dependendo da ordem em que os atributos são declarados na tabela, é possível omitir a lista de atributos na instrução INSERT INTO. Nesse caso, os valores devem ser inseridos na ordem em que os atributos foram declarados na tabela.
Por exemplo, se criarmos a tabela seguindo a ordem nome-salario-cargo:
CREATE TABLE empregado (
nome VARCHAR(30),
salario NUMERIC(8,2),
cargo VARCHAR(15)
);Poderemos inserir omitindo a lista de atributos, dês de que os valores estejam na ordem correta:
INSERT INTO empregado VALUES ('João', 2000.00, 'Analista');Mesmo exemplo, porém com uma tabela dentro de um Schema
INSERT INTO empresa.empregado VALUES ('João', 2000.00, 'Analista');Para caracteres usamos aspas simples!
"Frodo Bolseiro"
'Frodo Bolseiro'
Excluir Dados
DELETE FROM é usado para excluir registros (tupla/linha) de uma tabela (relação).
Sintaxe:
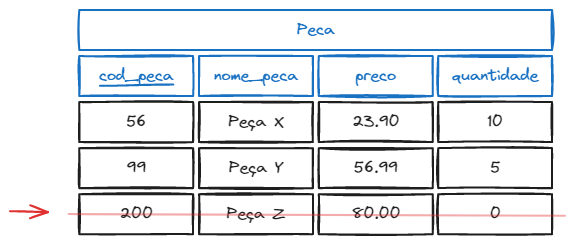
DELETE FROM nome_tabela WHERE condicao;Exemplo:
DELETE FROM peca WHERE cod_peca = 200;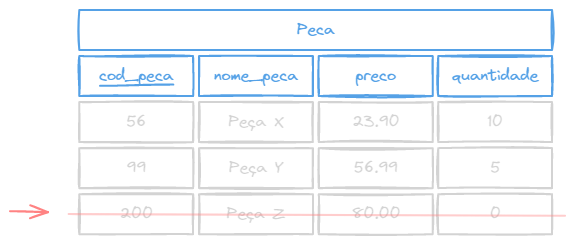
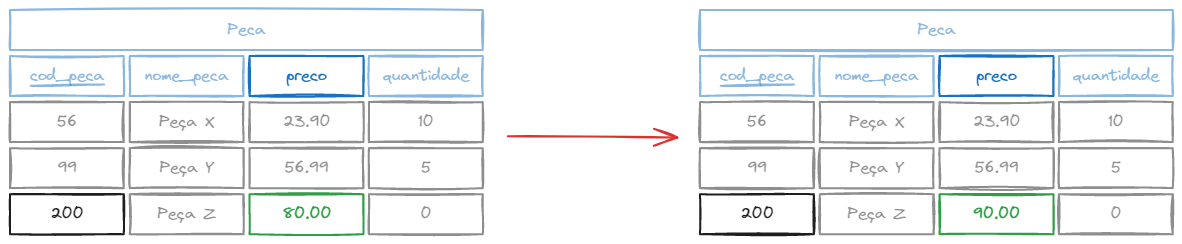
Atualizar dados
UPDATE/SET é usado para atualizar registros existentes em uma tabela. Quando há mudança de endereço, nome, etc...
Sintaxe:
UPDATE nome_tabela SET coluna1 = valor1, coluna2 = valor2 WHERE condicao;Exemplo:
UPDATE peca SET preco = 90.00 WHERE cod_peca = 200;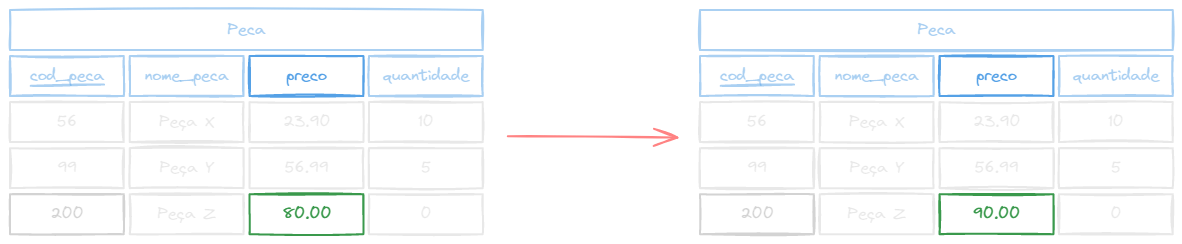
Selecionar dados
SELECT é usado para selecionar dados de um banco de dados. A instrução SELECT é usada para recuperar registros de uma ou mais tabelas.
Sintaxe:
SELECT coluna1, coluna2, ... FROM nome_tabela WHERE condicao;Exemplo:
SELECT nome_peca, quantidade FROM peca WHERE preco > 50;SELECT * FROM peca;O caractere * é um wildcard (coringa) usado para selecionar todos os atributos de uma tabela.
Cláusula WHERE (condição)
A cláusula WHERE é usada para filtrar registros. A cláusula WHERE é usada para extrair apenas os registros que atendem a uma condição específica.
Usa conectores lógicos:
AND- EOR- OUNOT- NÃO
Usa operadores de comparação:
>- Maior<- Menor=- Igual<=- Menor ou igual>=- Maior ou igual!=- Diferente (ou<>)BETWEEN- Entre um intervalo (incluindo os extremos). Facilita a especificação de condições númericas que envolvam um intervalo, ao invés de usar os operadores<=e>=.
Exemplos
Iremos fazer algumas operações de busca SELECT usando cláusulas de condição/filtro WHERE na tabela abaixo:
| cod_peca | nome_peca | preco | qtd |
|---|---|---|---|
| 56 | Peça X | 23.90 | 10 |
| 99 | Peça Y | 56.99 | 5 |
| 200 | Peça Z | 80.00 | 0 |
EXEMPLO 1 - Selecionar o código e o nome das peças com o preço menor que
SELECT cod_peca, nome_peca FROM peca WHERE preco < 70.00;Resultado:
| cod_peca | nome_peca |
|---|---|
| 56 | Peça X |
| 99 | Peça Y |
EXEMPLO 2 - Selecionar o nome e o preço das peças com preço maior que e menor do que
SELECT nome_peca, preco WHERE preco BETWEEN 50.00 AND 70.00Resultado:
| nome_peca | preco |
|---|---|
| Peça Y | 56.99 |
EXEMPLO 3 - Selecionar todas as informações das peças cuja quantidade em estoque seja maior ou igual a .
SELECT * FROM peca WHERE qtd >= 10;Resultado:
| cod_peca | nome_peca | preco | qtd |
|---|---|---|---|
| 56 | Peça X | 23.90 | 10 |
EXEMPLO 4 - Selecionar o código, nome, preço e quantidade de peças no estoque cujo código é .
SELECT cod_peca, nome_peca, preco, qtd FROM peca WHERE cod_peca = 200;Resultado:
| cod_peca | nome_peca | preco | qtd |
|---|---|---|---|
| 200 | Peça Z | 80.00 | 0 |
EXEMPLO 5 - Selecionar o nome e a quantidade de todas as peças que há no estoque.
SELECT nome_peca, quantidade FROM peca WHERE qtd != 0;ou...
SELECT nome_peca, quantidade FROM peca WHERE qtd <> 0;Resultado:
| nome_peca | quantidade |
|---|---|
| Peça X | 10 |
| Peça Y | 5 |
Cláusula ORDER BY (ordenação)
A cláusula ORDER BY é usada para ordenar o resultado de uma consulta em ordem crescente ou decrescente. Ela é aplicada somente à operações de consulta SELECT, após a cláusula WHERE.
Para especificar a forma de ordenação, devemos indicar
ASC- Crescente padrão - defaultDESC- Decrescente
Sintaxe:
SELECT coluna1, coluna2, ... FROM nome_tabela WHERE condicao ORDER BY coluna ASC|DESC;Exemplo:
SELECT nome_peca, quantidade FROM peca ORDER BY nome_peca DESC;Resultado:
| nome_peca | quantidade |
|---|---|
| Peça Z | 0 |
| Peça Y | 5 |
| Peça X | 10 |
Funções de agregação
As funções de agregação são usadas para calcular algo a partir de um conjunto de valores. As funções de agregação são usadas com a cláusula SELECT.
As principais são:
COUNT- Conta o número de linhas (tuplas)SUM- Soma os valores da coluna - apenas em dados numéricosAVG- Calcula a média dos valores da coluna (average3) - apenas em dados numéricosMIN- Retorna o menor valor da colunaMAX- Retorna o maior valor da coluna
Atenção SUM é diferente de COUNT
EXEMPLO 1 - Encontrar a soma dos preços de todas as peças, o maior preço, o menor preço e a média dos preços.
SELECT SUM(preco), MAX(preco), MIN(preco), AVG(preco) FROM peca;Resultado:
| SUM(preco) | MAX(preco) | MIN(preco) | AVG(preco) |
|---|---|---|---|
| 160.89 | 80.00 | 23.90 | 53.62999999995 |
EXEMPLO 2 - Contar o número de peças que há no estoque.
SELECT COUNT(*) FROM peca;ou
SELECT COUNT(cod_peca) FROM peca;Resultado:
| COUNT(*) | |
|---|---|
| 3 |
Cláusula DISTINCT (linhas únicas)
Linhas duplicadas podem aparecer nas relações. No caso de desejarmos a eliminação de duplicidade, devemos inserir a palavra DISTINCT na cláusula SELECT.
Observações
- Funções agregadas normalmente consideram as tuplas duplicadas.
- Não é permitido o uso do
DISTINCTcom oCOUNT(*). - É válido usar o
DISTINCTcomMAXouMIN, mesmo não alterando o resultado.
Tabela neste momento:
SELECT * FROM peca;| cod_peca | nome_peca | preco | qtd |
|---|---|---|---|
| 1 | Peça A | 15.00 | 10 |
| 2 | Peça B | 8.00 | 20 |
| 3 | Peça B | 8.00 | 10 |
| 4 | Peça A | 8.00 | 30 |
| 5 | Peça C | 17.00 | 0 |
| 6 | Peça C | 17.00 | null |
| 7 | Peça A | null | 15 |
Sinatxe:
SELECT DISTINCT coluna1, coluna2, ... FROM nome_tabela;Exemplo:
Selecionar o nome de todas as peças, sem o DISTINCT:
SELECT nome_peca FROM peca;| nome_peca | |
|---|---|
| Peça A | |
| Peça B | |
| Peça B | |
| Peça A | |
| Peça C | |
| Peça C | |
| Peça A |
Selecionar o nome de todas as peças, com o DISTINCT:
SELECT DISTINCT nome_peca FROM peca;| nome_peca | |
|---|---|
| Peça C | |
| Peça A | |
| Peça B |
Cláusula GROUP BY (agrupar)
A cláusula GROUP BY é usada para agrupar linhas que possuem o mesmo valor em uma ou mais colunas. É normalmente usada em conjunto com funções de agregação para agrupar os resultados de acordo com um ou mais campos. Desta forma, as funções de agregação será aplicada a cada grupo, e não a todas as tuplas.
Tabela neste momento:
SELECT * FROM peca ORDER BY nome_peca;| cod_peca | nome_peca | preco | qtd | veiculo |
|---|---|---|---|---|
| 1 | Peça A | 15.00 | 10 | CARRO |
| 2 | Peça B | 8.00 | 20 | MOTO |
| 3 | Peça C | 8.00 | 30 | CAMINHAO |
| 4 | Peça D | 8.00 | 10 | CARRO |
| 5 | Peça E | null | 15 | CAMINHAO |
| 6 | Peça F | 17.00 | 0 | MOTO |
| 7 | Peça G | 17.00 | null | CARRO |
Sintaxe:
SELECT coluna1, coluna2, ... FROM nome_tabela GROUP BY coluna1, coluna2, ...;EXEMPLO 1 - Selecionar o nome de todas as peças e agrupar por veículo (contar por grupo):
SELECT veiculo, COUNT(1) FROM peca GROUP BY veiculo;Resultado:
| veiculo | count |
|---|---|
| MOTO | 2 |
| CAMINHAO | 2 |
| CARRO | 3 |
EXEMPLO 2 - Obter a soma da quantidade de peças por tipo de veículo
SELECT veiculo, SUM(qtd) FROM peca GROUP BY veiculo;Resultado:
| veiculo | sum |
|---|---|
| MOTO | 20 |
| CAMINHAO | 45 |
| CARRO | 20 |
Cláusula HAVING (filtro)
A cláusula HAVING é usada para filtrar grupos de registros que resultam de uma operação de GROUP BY. A cláusula HAVING é usada em conjunto com a cláusula GROUP BY.
Sintaxe:
SELECT coluna1, coluna2, ... FROM nome_tabela GROUP BY coluna1, coluna2, ... HAVING condicao;EXEMPLO 2 anterior (alterado) - Obter a soma da quantidade de peças por tipo de veículo que sejam maiores que 20
SELECT veiculo, SUM(qtd) FROM peca GROUP BY veiculo HAVING SUM(qtd) > 20;Resultado:
| veiculo | sum |
|---|---|
| CAMINHAO | 45 |
Seleção com Junção
As vezes queremos retornar dados de mais de uma tabela, relacionando os dados de uma tabela com os dados de outra.
Para fazer a junção das tabelas, precisamos definir uma condição de junção, na qual os atributos chave primária (primary key) e chave estrangeira (foreign key) das relações devem ser relacionados.
Tabelas de exemplo
| num_tec | nome | cargo |
|---|---|---|
| 297 | Marco | Trainee |
| 553 | Hélio | Sênior |
| 062 | Tião | Sênior |
| 718 | Sílvio | Estagiário |
| num_tecnico | tipo | anos_exp |
|---|---|---|
| 553 | Secadora | 15 |
| 062 | Lavadora | 18 |
| 297 | Torradeira | 1 |
| 297 | Secadora | 1 |
| 718 | Lavadora | 5 |
| 062 | Congelador | 10 |
| 062 | Secadora | 12 |
| tipo | categoria | taxa |
|---|---|---|
| Lavadora | 1 | 20,00 |
| Secadora | 1 | 20,00 |
| Torradeira | 2 | 10,00 |
| Congelador | 1 | 8,00 |
| Batedeira | 2 | 25,00 |
Exemplo 1: Obter os nomes dos técnicos com experiência em secadora.
Query
SELECT nome FROM tecnicos, experiencia
WHERE num_tec = num_tecnico AND tipo = 'Secadora';Resultado
| Nome |
|-------|
| Hélio |
| Tião |Exemplo 2: Listar o nome dos técnicos e sua experiência em aparelhos da categoria 1
Query
SELECT tecnicos.nome, experiencia.anos_exp, tipos.tipo
FROM tecnicos, tipos, experiencia
WHERE
tipos.tipo = experiencia.tipo
AND
experiencia.num_tecnico = tecnicos.num_tec
AND
tipos.categoria = 1Repare que podemos utilizar a sintaxe tabela.atributo para especificar de qual tabela estamos selecionando o atributo.
SELECT tecnicos.nome, experiencia.anos_exp, tipos.tipo
FROM tecnicos, tipos, experiencia
WHERE
tipos.tipo = experiencia.tipo
AND
experiencia.num_tecnico = tecnicos.num_tec
AND
tipos.categoria = 1Resultado
| nome | anos_exp | tipo |
|--------|----------|-----------|
| Hélio | 15 | Secadora |
| Tião | 18 | Lavadora |
| Marco | 1 | Secadora |
| Sílvio | 5 | Lavadora |
| Tião | 12 | Secadora |Uso de aliases (apelido)
Alias são apelidos que podemos dar aos atributos na hora de retornar valores no SELECT, permite associar um "nome de variável" para cada relação, a fim de simplificar comandos SQL, e torna o retorno mais legível.
Para criarmos um alias podemos usar a palavra reservada AS. Criando um SELECT com alias temos:
Alias para tabelas
SELECT T.nome, E.anos_exp, TP.tipo
FROM
tecnicos AS T,
tipos AS TP,
experiencia AS E
WHERE TP.tipo = E.tipo
AND E.num_tecnico = T.num_tec
AND TP.categoria = 1;Alias para atributos
SELECT
tecnicos.nome AS Tecnico,
experiencia.anos_exp AS Experiencia,
tipos.tipo AS Tipo
FROM tecnicos, tipos, experiencia
WHERE tipos.tipo = experiencia.tipo
AND experiencia.num_tecnico = tecnicos.num_tec
AND tipos.categoria = 1;nome | anos_exp | tipo Tecnico | Experiencia | Tipo
-----|----------|------ --------|-------------|------
... | ... | ... ... | ... | ...
... | ... | ... -> ... | ... | ...
... | ... | ... ... | ... | ...
... | ... | ... ... | ... | ...Limitando o número de linhas
Em alguns casos, é necessário limitar o número de linhas retornadas em uma consulta. Para isso, podemos usar a cláusula LIMIT.
Sintaxe:
SELECT coluna1, coluna2, ... FROM <tabela> LIMIT <número de linhas>;Exemplo:
SELECT * FROM peca LIMIT 5;Pulando linhas
Podemos também pular um número de linhas no início da consulta, usando a cláusula OFFSET.
Sintaxe:
SELECT coluna1, coluna2, ... FROM <tabela> OFFSET <número de linhas>;Exemplo:
SELECT * FROM peca ORDER BY nome OFFSET 3;Comando LIKE
Quando desejamos pesquisar uma substring de um texto, podemos usar o comando LIKE ou NOT LIKE. Ele é usado para comparar um valor de texto com um padrão.
Utilizamos o sinal % para representar zero ou mais caracteres e o sinal de _ para representar um único caractere.
Sintaxe:
SELECT coluna1, coluna2, ... FROM <tabela> WHERE coluna LIKE <padrão>;Exemplo
Imagine que temos a seguinte tabela no banco de dados:
| cod_pessoa | nome | data_nasc | profissao |
|---|---|---|---|
| 1 | Capitão Jack Sparrow | 1710-01-01 | Comerciante de rum |
| 2 | Anakin Skywalker | 41 ABY | Mestre Jedi |
| 3 | Legolas | 87 - 3ª era | Arqueiro |
| 4 | Elliot Alderson | 1985-09-17 | Engenheiro de segurança |
| 5 | Harvy Specter | 1972-03-12 | Advogado |
| 6 | Anthony Edward Stark | 1970-05-29 | Bilionário, playboy, filantropo |
| 7 | Gustavo Fring | 1958-04-26 | Distribuidor farmacêutico |
| 8 | Batman | 1972-02-19 | Bruce Wayne |
E queremos retornar todoas as pessoas que possuem a letra e no nome.
SELECT * FROM pessoa WHERE nome LIKE '%e%';Resultado:
cod_pessoa | nome | data_nasc | profissao
-----------|-----------------|--------------|-----------
3 | Legolas | 87 - 3ª era | Arqueiro
4 | Elliot | 1985-09-17 | Engenheiro de segurança
5 | Harvy Specter | 1972-03-12 | AdvogadoValores condicionais (CASE)
O comando CASE é uma expressão condicional que retorna um valor único com base em uma ou mais condições. Ele é usado para substituir valores de uma coluna por outro valor, com base em uma condição.
Sintaxe:
SELECT coluna1, coluna2, ...,
CASE
WHEN condicao1 THEN valor1
WHEN condicao2 THEN valor2
ELSE valor_padrao
END
FROM <tabela>;Exemplo
SELECT
nome,
idade,
CASE
WHEN idade < 30 THEN 'Jovem'
WHEN idade < 60 THEN 'Adulto'
WHEN idade < 200 THEN 'Idoso'
ELSE 'Imortal'
END AS faixa_etaria
FROM pessoa;nome | idade | faixa_etaria
---------------|-------|-------------
Elliot | 36 | Adulto
Tony Stark | 51 | Adulto
Legolas | 300 | Imortal
Gustavo Fring | 64 | Idoso
Robbin | 25 | JovemObservações
Uma consulta em SQL pode consistir em até seis cláusulas:
SELECT [*] [DISTINCT] <lista de atributos> <funções de agregação>
FROM <lista de tabelas>
[WHERE <condição>]
[GROUP BY <lista de atributos para agrupamento>]
[HAVING <condição para agrupamento, aceita funções de agregação>]
[ORDER BY <lista de atributos para ordenação>] [ASC] [DESC]- Apenas as cláusulas
SELECTeFROMsão obrigatórias - Quando existentes, as cláusulas devem aparecer na ordem específica acima.
- O
ORDER BYsó pode ser ultilizado após o últimoSELECT(se a linguagem permitir) - As cláusulas
GROUP BYeHAVINGsó podem ser usadas nos comandosSELECTindividuais
Retornando dados alterados
Em alguns caso, é necessário retornar dados que foram alterados (inseridos, atualizados, deletados). Para isso podemos usar a cláusula RETURNING ao final da nossa query de alteração.
Sintaxe:
INSERT INTO <nome da tabela> (...) VALUES (...) RETURNING coluna1, coluna2, ...;Exemplo:
INSERT INTO peca (nome_peca, preco, qtd)
VALUES ('Peça H', 10.00, 5)
RETURNING cod_peca;UPDATE peca SET preco = 90.00
WHERE cod_peca = 200
RETURNING nome_peca;DELETE FROM peca WHERE cod_peca = 200 RETURNING nome_peca;A sintaxe do RETURNING é a mesma que a do SELECT, ou seja, podemos retornar qualquer coluna da tabela que foi alterada.
Valores NULL (nulo)
Suponhamos que temos a tabela Peça criada anteriormente, estruturada e preenchida da seguinte forma:
| Coluna (tupla) | Data Type (Tipo) | Length/Precision (Comprimento) | Scale (Escala) | Not Null? (Não Nulo?) | Primary Key? (Chave Primária?) | Default (Padrão) |
|---|---|---|---|---|---|---|
| cod_peca | INTEGER | Sim | Sim | |||
| nome_peca | VARCHAR | 30 | Sim | Não | ||
| preco | NUMERIC | 6 | 2 | Não | Não | |
| qtd | INTEGER | Não | Não | 0 |
| cod_peca | nome_peca | preco | qtd |
|---|---|---|---|
| 1 | Peça A | 15.00 | 10 |
| 2 | Peça B | 8.00 | 20 |
| 3 | Peça C | 8.00 | 30 |
| 4 | Peça D | 8.00 | 10 |
Código SQL
CREATE TABLE peca (
cod_peca INTEGER NOT NULL,
nome_peca VARCHAR(30) NOT NULL,
preco NUMERIC(6,2),
qtd INTEGER DEFAULT 0
);INSERT INTO peca VALUES
(1, 'Peça A', 15.00, 10),
(2, 'Peça B', 8.00, 20),
(3, 'Peça C', 8.00, 30),
(4, 'Peça D', 8.00, 10);Inserindo valores nulos
Quando realizamos um INSERT e não passamos o campo, o banco de dados vai automaticamente inserir NULL no valor da célula.
INSERT INTO peca (cod_peca, nome_peca, qtd) VALUES (5, 'Peça E', 15);Resultado:
| cod_peca | nome_peca | preco | qtd |
|---|---|---|---|
| 1 | Peça A | 15.00 | 10 |
| 2 | Peça B | 8.00 | 20 |
| 3 | Peça C | 8.00 | 30 |
| 4 | Peça D | 8.00 | 10 |
| 5 | Peça E | null | 15 |
Cuidado com o DEFAULT!
Lembre-se que colunas que tem o valor DEFAULT definido, não serão preenchidas com NULL, mas sim com o valor DEFAULT especificado no momento da criação da tabela.
INSERT INTO peca (cod_peca, nome_peca, preco) VALUES (6, 'Peça F', 20.00);Resultado:
| cod_peca | nome_peca | preco | qtd |
|---|---|---|---|
| 1 | Peça A | 15.00 | 10 |
| 2 | Peça B | 8.00 | 20 |
| 3 | Peça C | 8.00 | 30 |
| 4 | Peça D | 8.00 | 10 |
| 5 | Peça E | null | 15 |
| 6 | Peça F | 20.00 | 0 |
Existe um outra forma de definir um valor como NULL. Deixando explícito no comando INSERT que a coluna deve receber o valor NULL.
INSERT INTO peca (cod_peca, nome_peca, preco, qtd) VALUES (7, 'Peça G', 17.00, NULL);Resultado:
| cod_peca | nome_peca | preco | qtd |
|---|---|---|---|
| 1 | Peça A | 15.00 | 10 |
| 2 | Peça B | 8.00 | 20 |
| 3 | Peça C | 8.00 | 30 |
| 4 | Peça D | 8.00 | 10 |
| 5 | Peça E | null | 15 |
| 6 | Peça F | 20.00 | 0 |
| 7 | Peça G | 17.00 | null |
Repare que mesmo o campo qtd possuindo um valor DEFAULT, foi definido de forma explícita no INSERT que essa coluna deveria possuir um valor NULL.
Atenção! - Mesmo se você tentar inserir o valor NULL em uma coluna definida como NOT NULL, uma exceção (erro) será lançada pelo banco de dados.
INSERT INTO peca (cod_peca, nome_peca, preco, qtd) VALUES (7, NULL, 17.00, 12);Resultado:
ERROR: null value in column "nome_peca" of relation "peca" violates not-null constraint
DETAIL: Failing row contains (7, null, 17.00, 12).
SQL state: 23502Selecionando valores nulos
Caso você queira selecionar somente as linhas com valores nulos em uma determinada célula, a forma correta é utilizar o IS NULL, e não ... = NULL.
SELECT * FROM peca WHERE preco IS NULL;SELECT * FROM peca WHERE preco = NULL;Selecionando valores não nulos
Caso você queira selecionar apenas as linhas que não possuem valores nulos em uma determinada coluna, é só utilizar o c omando IS NOT NULL.
SELECT * FROM peca WHERE preco IS NOT NULL;Resultado:
| cod_peca | nome_peca | preco | qtd |
|---|---|---|---|
| 1 | Peça A | 15.00 | 10 |
| 2 | Peça B | 8.00 | 20 |
| 3 | Peça C | 8.00 | 30 |
| 4 | Peça D | 8.00 | 10 |
| 6 | Peça F | 20.00 | 0 |
| 7 | Peça G | 17.00 | null |
Repare que a peça de código não foi incluída no resultado, por possuir o valor null na coluna preco.
Ordenando colunas com NULL
Por default, caso você ordene um SELECT por uma coluna que possui células com valor NULL, essas células serão as últimas a serem retornadas.
SELECT * FROM peca ORDER BY preco;Resultado:
| cod_peca | nome_peca | preco | qtd |
|---|---|---|---|
| 4 | Peça D | 8.00 | 10 |
| 2 | Peça B | 8.00 | 20 |
| 3 | Peça C | 8.00 | 30 |
| 1 | Peça A | 15.00 | 10 |
| 6 | Peça F | 20.00 | 0 |
| 7 | Peça G | 17.00 | null |
| 5 | Peça E | null | 15 |
Caso você deseje que as células com valores NULL sejam as primeiras a serem retornadas no SELECT, utilizamos o ORDER BY ... NULLS FIRST.
SELECT * FROM peca ORDER BY preco NULLS FIRST;Resultado:
| cod_peca | nome_peca | preco | qtd |
|---|---|---|---|
| 5 | Peça E | null | 15 |
| 2 | Peça B | 8.00 | 20 |
| 3 | Peça C | 8.00 | 30 |
| 4 | Peça D | 8.00 | 10 |
| 1 | Peça A | 15.00 | 10 |
| 6 | Peça F | 20.00 | 0 |
| 7 | Peça G | 17.00 | null |
Substituindo valores nulos
Em alguns casos é necessário substituir os valores NULL por outro valor, quando usarmos o SELECT ou o RETURNIG. Para isso, podemos usar a função COALESCE.
Sintaxe
SELECT COALESCE(<coluna>, <valor substituido>) FROM <tabela>;Exemplo:
SELECT codigo, telefone FROM professor;| codigo | telefone |
|--------|----------|
| 1 | 37999999 |
| 2 | [null] |SELECT codigo, COALESCE(telefone, 'NÃO CADASTRADO') FROM professor;| codigo | telefone |
|--------|----------------|
| 1 | 37999999 |
| 2 | NÃO CADASTRADO |
Junções (Comando JOIN)
Junção é a possibilidade de se criar relacionamentos entre tabelas, de forma a poder recuperar dados de mais de uma tabela em uma única consulta. Um jeito melhor e nativo de se juntar mais de uma tabela, diferente do método apresentado no capítulo Seleção com Junção.
Isso é possível atravez do comando JOIN (junção), que é usado para combinar linhas de duas ou mais tabelas com base em uma relação entre elas, e recuperando esses dados usando apenas um SELECT.
É importante utilizá-lo, porque tira da cláusula WHERE condições que são estritamente das junções (chave primária igual a chave estrangeira, por exemplo).
Existem as variações de junções internas e externas.
Internas: INNER JOIN e NATURAL JOIN
Externas: OUTER JOIN (LEFT, RIGHT, FULL)
Como funciona o comando JOIN?
Quando um comando SELECT especifica campos de duas tabelas sem nenhumas restrição ou filtro, o resultado será um número de linhas iguais à multiplicação do total de linhas da primeira tabela () pela segunda tabela (), ou seja .
Isso ocorre devido ao fato de que, para cada linha da primeira tabela, todas as linhas da segunda são processadas. Operações de junção toma duas relações, e têm como resultado uma outra relação.
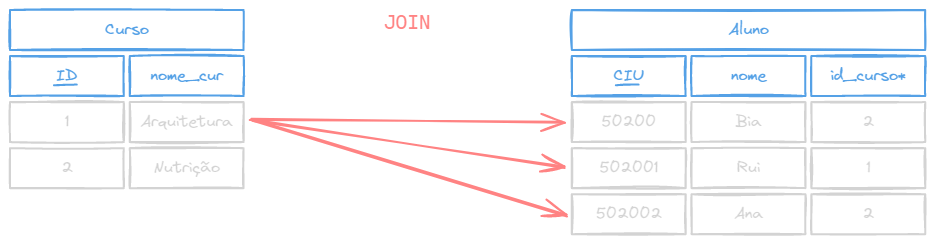
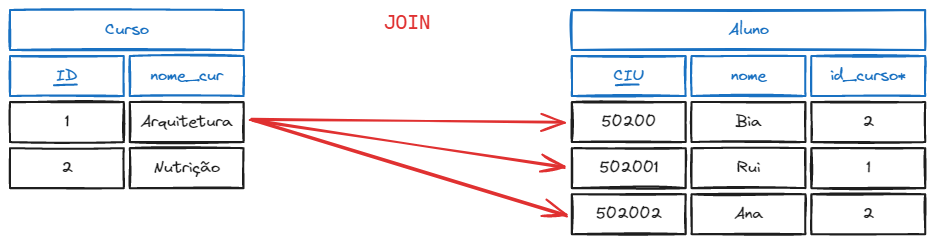
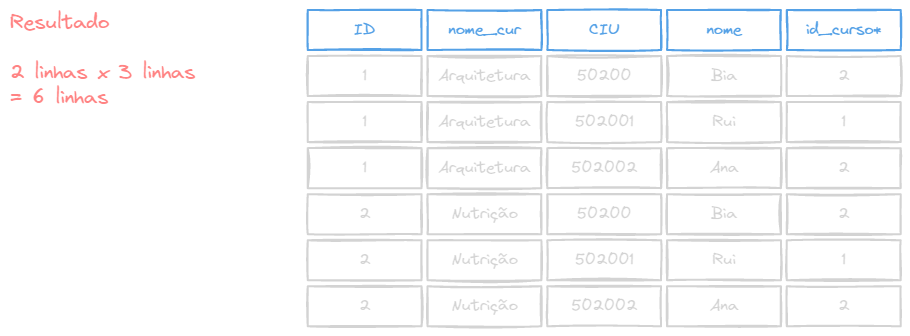
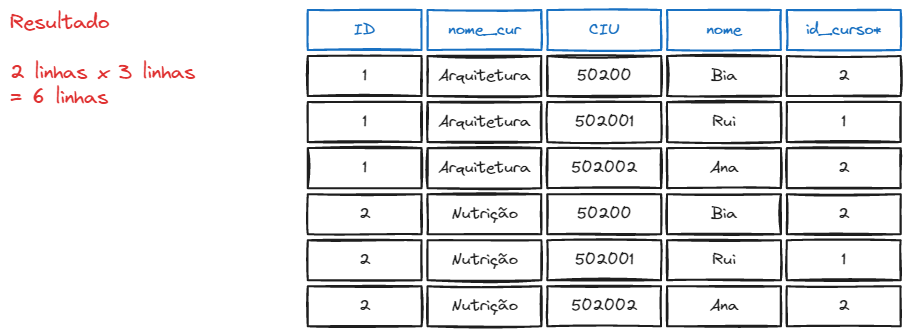
Porém, o benefício do JOIN só será sentido quando as chaves e forem equivalentes, ou seja, , usando a palavra reservada ON (será explicado mais a frente).
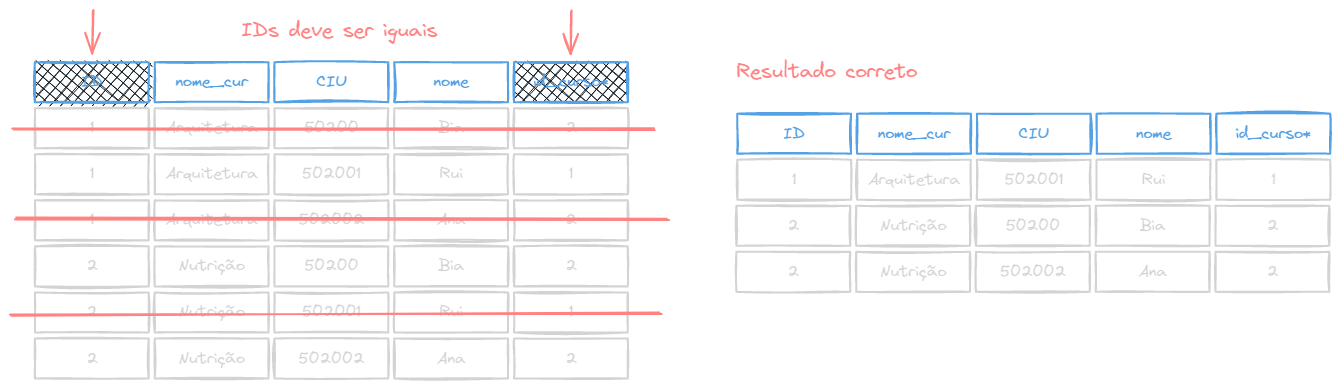
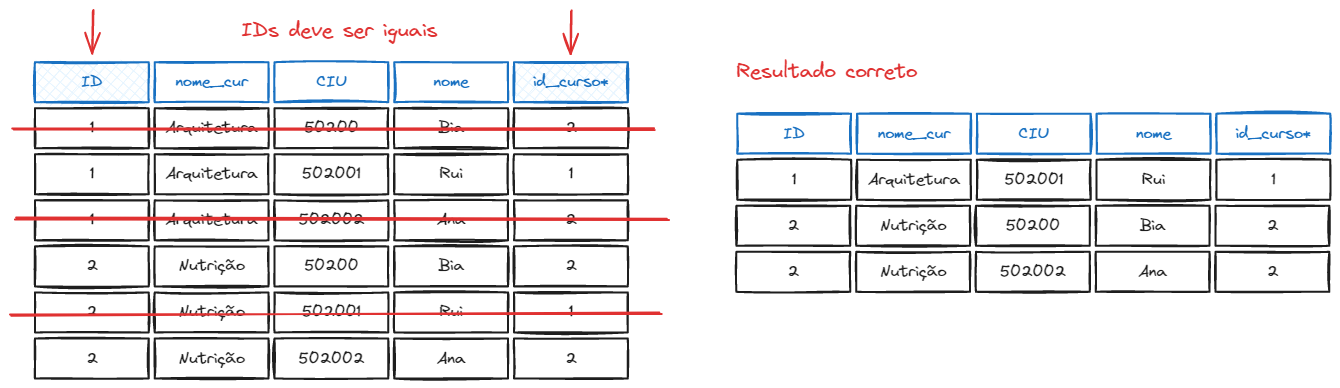
A operção de junção tem algumas variantes, e cada uma dessas variações consiste em um tipo de junção e uma condição de junção.
Sintaxe
SELECT coluna1, coluna2, ...
FROM tabela1 <tipo> JOIN tabela2
ON <condição>;Exemplo
SELECT nome, nasc, experiencia
FROM tecnicos INNER JOIN experiencia
ON tecnicos.num_tec = experiencia.num_tecnico;TIPO DE JUNÇÃO (INNER ou OUTER)
Define como as tuplas em cada relação que não possuam nenhuma conrrespondência com as tuplas da outra relação deve ser tratadas.
CONDIÇAO DE JUNÇAO (ON)
Definem quais tuplas das duas relações apresentam correspondência e quais atributos são apresentados de uma junção.
INNER JOIN
O INNER JOIN (Ou somente JOIN) é uma junção interna, que junta os registros de uma tabela que tiver um correspondente na outra tabela, através da chave primária e estrangeira.
Por exemplo, a tabela abaixo é resultado de um JOIN de 2 outras tabelas. A segunda tabela possui chaves estrangeiras apontando para valores nulos, e a primeira possui tuplas sem conrrespondência na segunda tabela. O resultado do INNER JOIN será apenas as linhas que possuem corrêspondência nas duas tabelas:

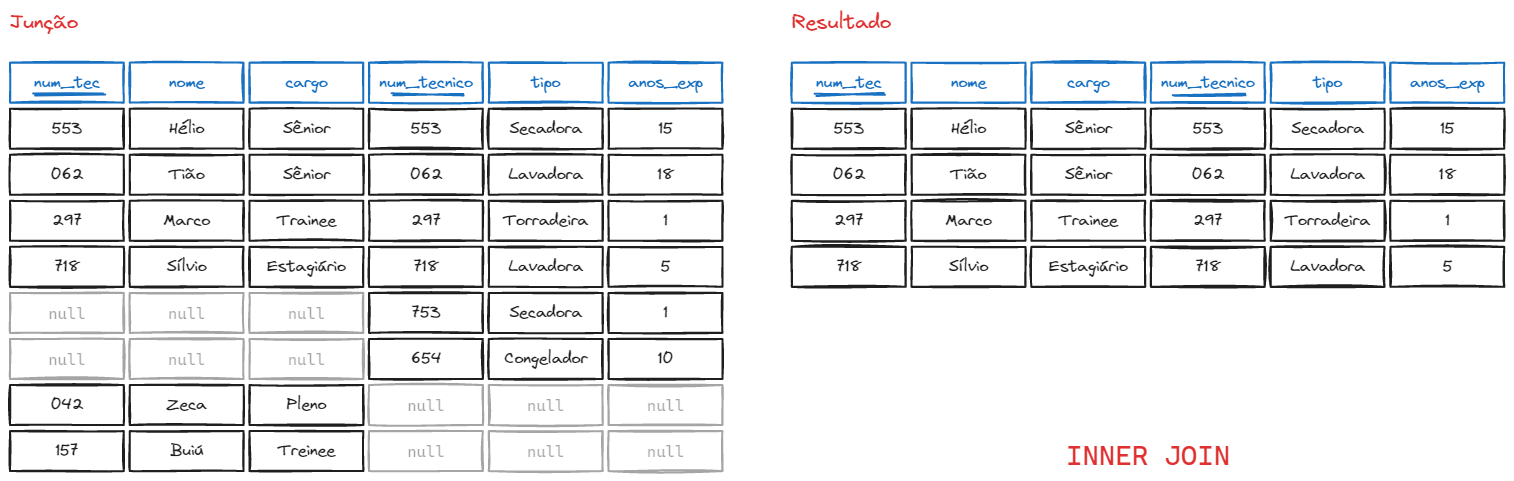
Sintaxe
SELECT coluna1, coluna2, ...
FROM (tabela1 INNER JOIN tabela2
ON tabela1.chave_primaria = tabela2.chave_estrangeira);A palavra INNER pode ser omitida
SELECT coluna1, coluna2, ...
FROM (tabela1 JOIN tabela2
ON tabela1.chave_primaria = tabela2.chave_estrangeira);Usando o INNER JOIN com 2 tabelas
Exemplo: Liste o nome dos técnicos que possuem experiência em Lavadora
Tabelas
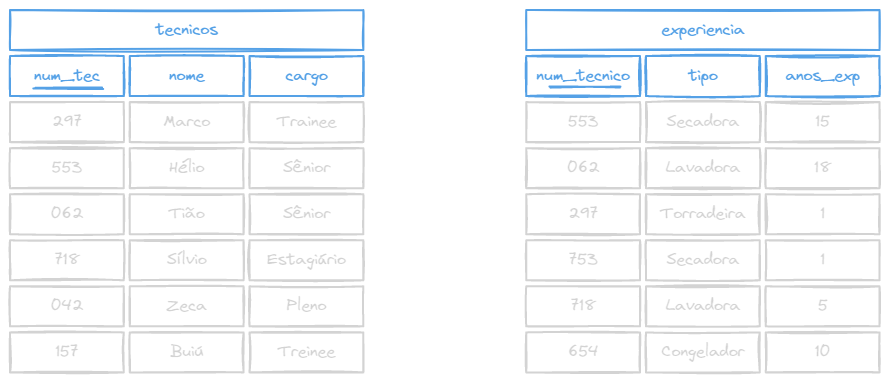
Query
SELECT nome
FROM (tecnicos INNER JOIN experiencia
ON tecnicos.num_tec = experiencia.num_tecnico)
WHERE experiencia.tipo = 'Lavadora';Resultado


Usando o INNER JOIN com 3 tabelas
Exemplo: Liste o nome dos técnicos e sua experiência em aparelhos da categoria 1
Tabelas
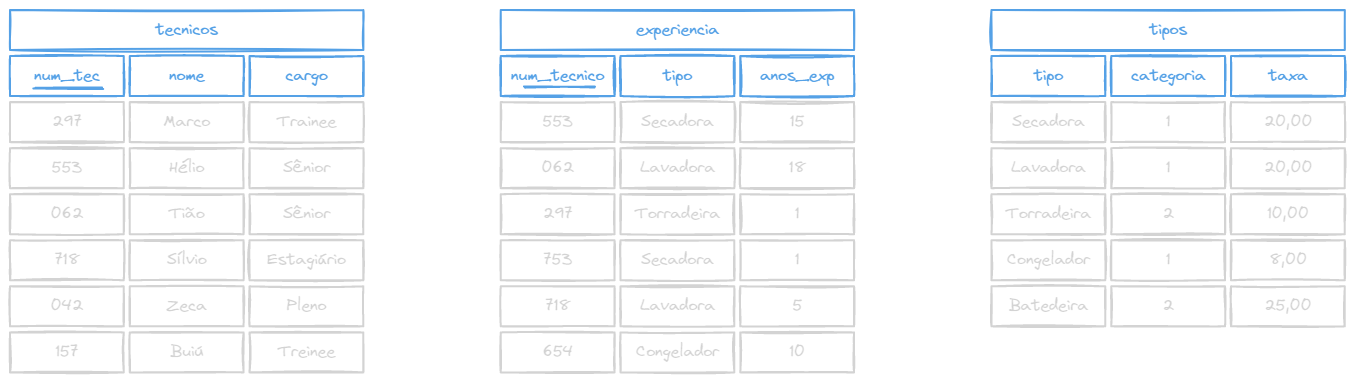

Query
SELECT nome, anos_exp
FROM ((tecnicos INNER JOIN experiencia
ON num_tec = num_tecnico) INNER JOIN Tipos
ON tipo = tipo)
WHERE categoria = 1;Resultado
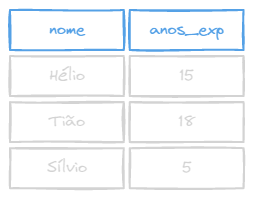
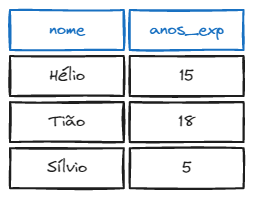
NATURAL JOIN
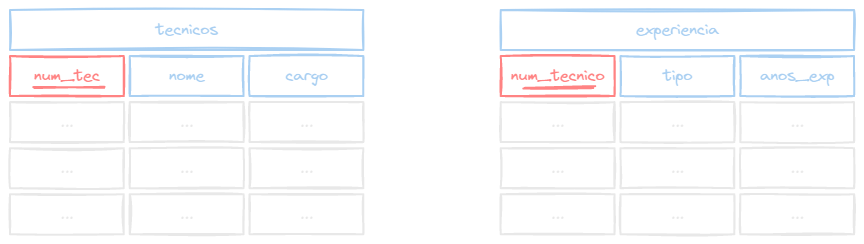
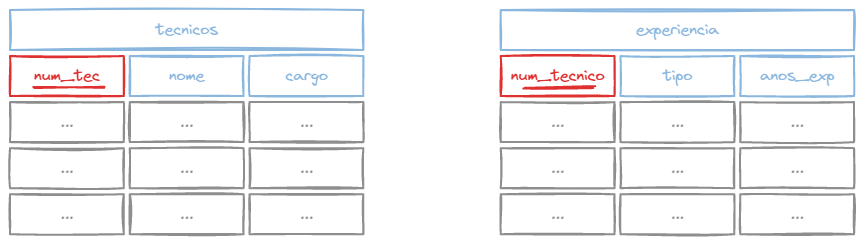
Com ele você não precisa identificar quais colunas serão comparadas, pois ele fará a comparação entre campos com o mesmo nome.
Sintaxe
SELECT coluna1, coluna2...
FROM tabela1 NATURAL JOIN tabela2;Exemplo
SELECT * FROM (tecnicos NATURAL JOIN experiencia);Repare que não precisamos passar a condição de junção com ON, já que ambas as tabelas possuem a coluna tipo.
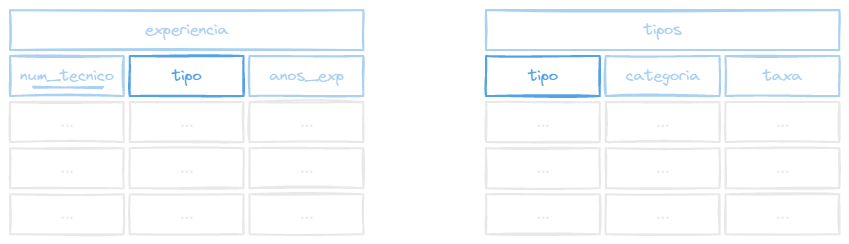
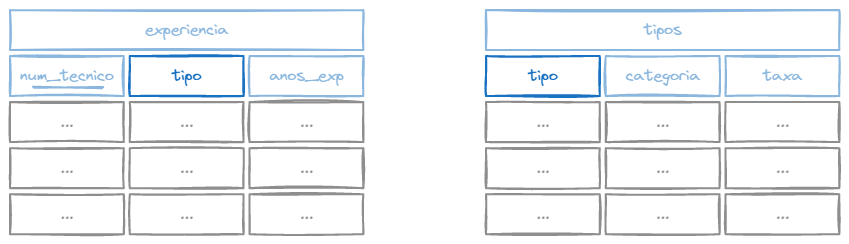
O mesmo não da pra ser feito entre as tabelas tecnicos e tipos, pois não possuem colunas com o mesmo nome.
OUTER JOIN
O OUTER JOIN é a variação de junção externa, e é composto por 3 tipos:
LEFT OUTER JOINRIGHT OUTER JOINFULL OUTER JOIN
A palavra OUTER pode ser omitida em todos os 3 tipos
Diferente das junções internas, como o INNER JOIN, as junções externas podem retornar valores mesmo quando não há conrrespondência entre as tabelas (valores NULL).
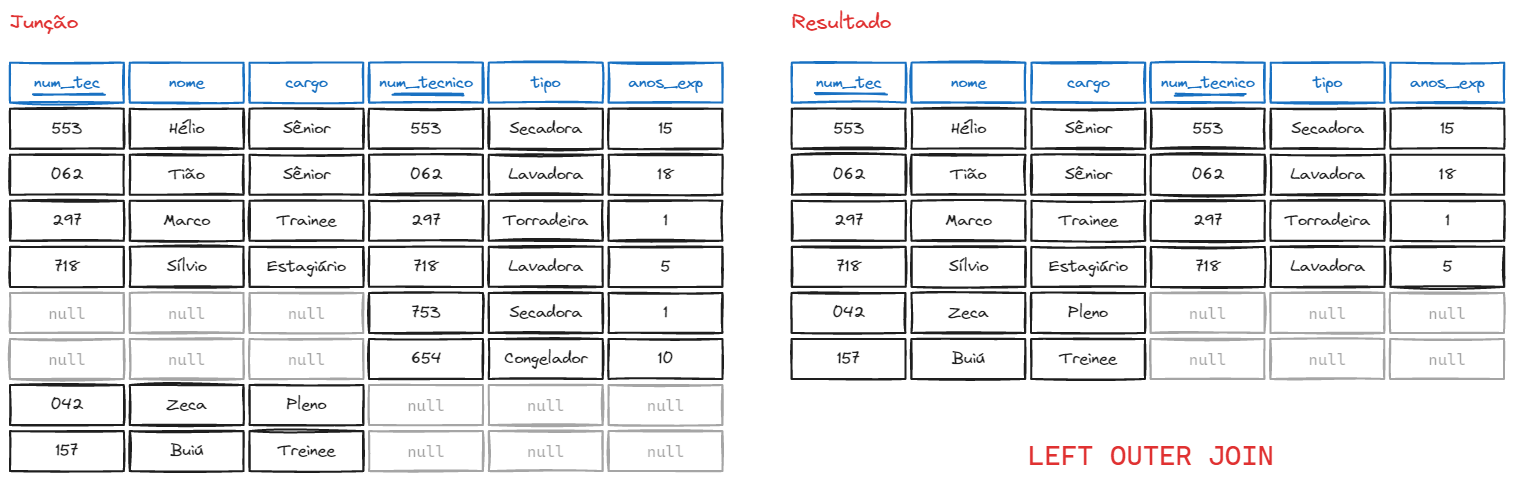
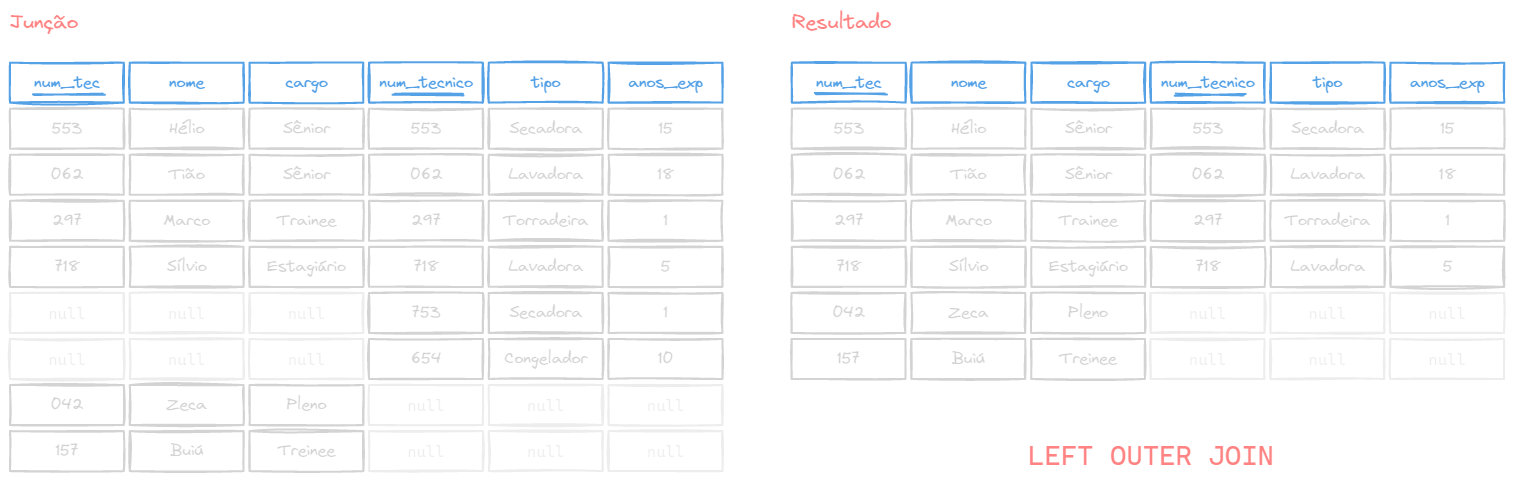
LEFT OUTER JOIN
No LEFT OUTER JOIN (ou simplesmente LEFT JOIN), a prioridade é da tabela da esquerda, isto é, todos os registros da primeira tabela serão mostrados independente se houver correspondente nas outra tabela, após a equivalência das chaves usando o ON.
Sintaxe
SELECT coluna1, coluna2...
FROM tabela1 LEFT OUTER JOIN tabela2;Exemplo
SELECT * FROM (tecnicos LEFT OUTER JOIN experiencia);RIGHT OUTER JOIN
No RIGHT OUTER JOIN (ou simplesmente RIGHT JOIN), a prioridade é da tabela da direita, isto é, todos os registros da segunda tabela serão mostrados independente se houver correspondente na outra tabela.
Pega todos os atributos da relação que está à direita, verifica se existe algum correspondente à esquerda, caso afirmativo, retorna os atributos da esquerda, e caso negativo, coloca o valor nulo nos atributos.
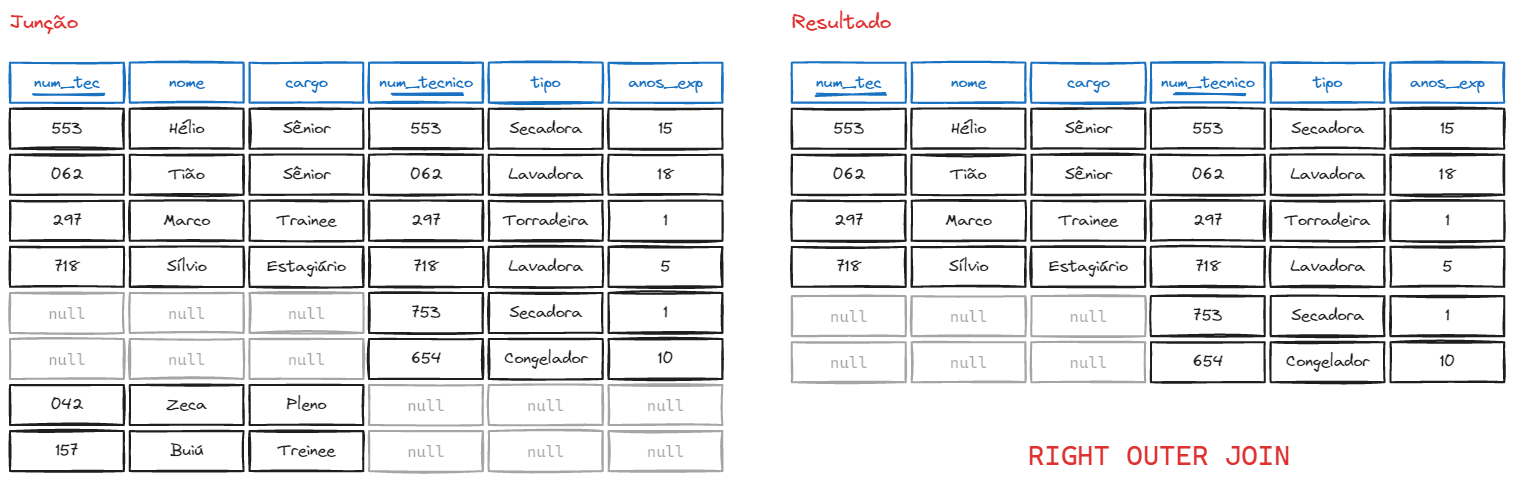
Sintaxe
SELECT coluna1, coluna2...
FROM tabela1 RIGHT OUTER JOIN tabela2;Exemplo
SELECT * FROM (tecnicos RIGHT OUTER JOIN experiencia);FULL OUTER JOIN
Faz o RIGHT e o LEFT ao mesmo tempo, ou seja, vai retornar dados que não tem em comum nas duas tabelas, e não só na tabela da direita ou da esquerda.
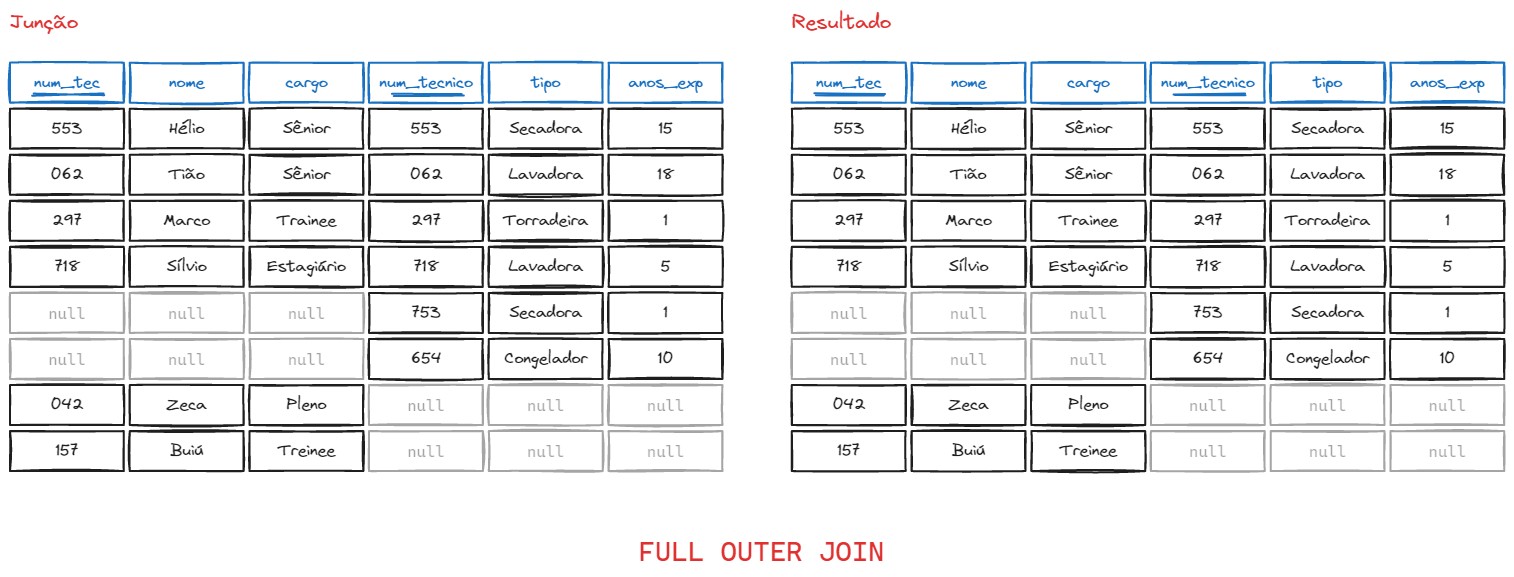

Sintaxe
SELECT coluna1, coluna2...
FROM tabela1 FULL OUTER JOIN tabela2;Exemplo
SELECT * FROM (tecnicos FULL OUTER JOIN experiencia);Funções Matemáticas
| Função | Descrição | Exemplo |
|---|---|---|
ABS(x) | Retorna o valor absoluto de | ABS(-5) retorna 5 |
ROUND(x) | Retorna arredondado | ROUND(5.5) retorna 6 |
ROUND(x, d) | Retorna arredondado para casas decimais | ROUND(5.3, 0) retorna 5 |
CEIL(x) | Retorna o menor número inteiro maior ou igual a | CEIL(5.3) retorna 6 |
FLOOR(x) | Retorna o maior número inteiro menor ou igual a | FLOOR(5.3) retorna 5 |
FACTORIAL(x) | Retorna o fatorial de | FACTORIAL(5) retorna 120 |
TRUNC(x, d) | Retorna truncado para casas decimais | TRUNC(5.3, 0) retorna 5 |
MOD(x, y) | Retorna o resto da divisão de por | MOD(5, 2) retorna 1 |
PI() | Retorna o valor de | PI() retorna 3.141592653589793 |
LOG(x) | Retorna o logaritmo natural de | LOG(10) retorna 2.302585092994046 |
RANDOM() | Retorna um número aleatório entre 0 e 1 | RANDOM() retornar algo como 0.123456789 |
Consulte a documentação oficial do PostgreSQL para mais funções.
Funções de String
| Função | Descrição | Exemplo |
|---|---|---|
CHARACTER_LENGTH(string) ou CHAR_LENGHT(string) | Retorna o número de caracteres em string | CHARACTER_LENGTH('Hello') retorna 5 |
LOWER(string) | Retorna string em minúsculo | LOWER('Hello') retorna hello |
UPPER(string) | Retorna string em maiúsculo | UPPER('Hello') retorna HELLO |
POSITION(substring IN string) | Retorna a posição da primeira ocorrência de substring em string | POSITION('l' IN 'Hello') retorna 3 |
SUBSTRING(string FROM start FOR length) | Retorna uma parte de string, onde start determina a posicão do primeiro caractere e length determina quantos caracteres serão usados apartir de start | SUBSTRING('Hello' FROM 2 FOR 3) retorna ell |
CONCAT(string1, string2, ...) | Concatena string1, string2 e outras strings posteriores | CONCAT('Hello', ' ', 'World') retorna Hello World |
Consulte a documentação oficial do PostgreSQL para mais funções.
Conversão de dados
Existem alguns métodos para se converter um tipo de um dado em outro. O mais comum é utilizando a função CAST, que converte um valor de um tipo de dado para outro.
Sinatxe
CAST(valor AS tipo_de_dado);Onde valor é o valor que será convertido e tipo_de_dado é o tipo para o qual o valor será convertido. Exemplo:
CAST('5' AS NUMERIC);Repare que no exemplo acima, '5' está como string por causa das aspas simples ', e queremos converter para um inteiro.
O mesmo pode ser feito utilizando a sintaxe valor::tipo, onde valor é o valor que será convertido e tipo é o tipo para o qual o valor será convertido. Exemplo:
5::TEXT;Aqui, 5 está como inteiro, e estamos convertendo para o formato texto (string).
Formato de dados
to_char ( timestamp, formato ) → texto
to_char ( timestamp com fuzo horário, formato ) → texto
to_char(timestamp '2002-04-20 17:31:12.66', 'HH12:MI:SS') → 05:31:12to_char ( intervalor, formato ) → texto
to_char(interval '15h 2m 12s', 'HH24:MI:SS') → 15:02:12to_char ( numeric_type, text ) → text
to_char(125, '999') → 125
to_char(125.8::real, '999D9') → 125.8
to_char(-125.8, '999D99S') → 125.80-to_char ( numeric_type, text ) → text
to_char(125, '999') → 125
to_char(125.8::real, '999D9') → 125.8
to_char(-125.8, '999D99S') → 125.80-to_date ( texto, data ) → data
to_date('05 Dec 2000', 'DD Mon YYYY') → 2000-12-05to_number ( texto, formato ) → numero
to_number('12,454.8-', '99G999D9S') → -12454.8to_timestamp ( texto, formato ) → timestamp com fuso horário
to_timestamp('05 Dec 2000', 'DD Mon YYYY') → 2000-12-05 00:00:00-05Consulte a documentação oficial do PostgreSQL para ver a tabela de template de formatos.
Footnotes
-
CRUD é a abreviatura de Create, Read, Update e Delete. É um acrônimo que se refere às quatro funções básicas de um sistema de banco de dados: Criar, Ler, Atualizar e Excluir. ↩
-
DBA é a abreviatura de Database Administrator (Administrador de Banco de Dados.) ↩
-
Average é a palavra em inglês para média. ↩